Grafana: (3) 变量的创建、管理与使用
Grafana: (3) 变量的创建、管理与使用
建议点击 查看原文 查看最新内容。
原文链接: https://typonotes.com/posts/2023/06/08/grafana-variable-management/
之前在 Grafana: (1) DataSource 数据源管理 中提到过, 对于不同环境的的数据源命名是具有一定规则, 可以在后期通过变量管理。
这个需求其实很好理解:
- 不同的团队 对定制的监控界面有各自的需求, 大部分情况下 不能混用 。
- 而某个团队的 不同环境 的界面 又需要一致, 这样使用起来没有额外学习成本。
在面板中 引入变量, 能快速切换不同环境, 还能对更好的过滤查询条件。 这点很容易理解。
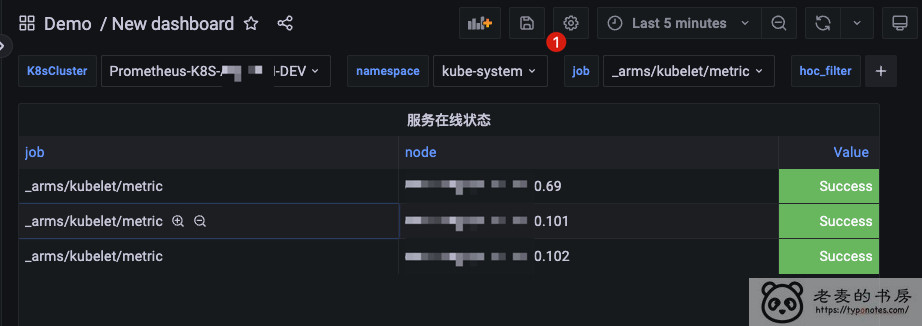
1. Grafana 变量
Grafana 给出了 9种内置变量类型 , 个人比较常用的有一下几种
- Global Variables: 内置全局变量
- Data Source: 数据源
- Query: 查询
- Interval: 间隔
- Ad hoc filters: 条件过滤
2. Grafana 变量配置
在 Dashboard 右上角 点击 齿轮/Dashboard Setting 进入配置界面, 选择 变量/Variables。
点击 Add Variable 或者 New 创建变量
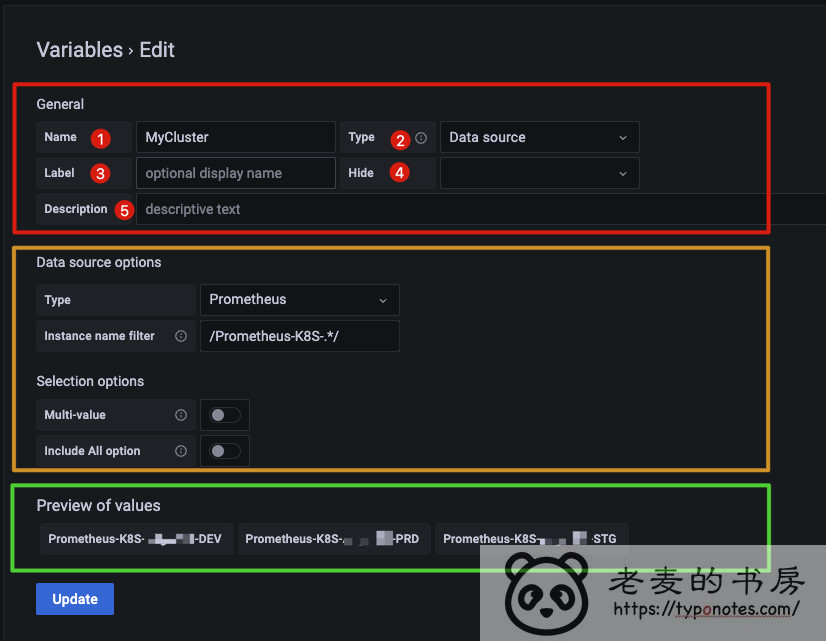
可以认为分为 三个区 或者 四个区(按名字)
- 红区: 对变量的定义, 描述
- 黄区: 对于变量的过滤或补充。 不同类型的变量这部分不同。
- 绿区: 结果预览。
重点说一下 红区
- Name: 变量名称。 一定要用有 语义 的 单词或词组, 方便后期使用和展示。
- Label: Dashboard 上的显示名称, 如果为空则显示 Name。 这部分我通常不写。 变量名已经有了明确的意思, 直接用变量名更方便。
- Description: 变量描述。 这部分类似注释, 可以多写一些提示性语句。
- Type: 变量类型 。
- Hide: 是否隐藏。 一些 不需要用户控制 的变量就可以隐藏。 后面会有一个案例说明。
2.1. DataSource数据源 变量
我们创建一个 数据源变量。 直接看图, 很直观了。
实际上, 在没有过滤之前, 我拥有 十多个 Prometheus 的变量。
2.2. Query/查询 变量
Query 变量应该是用的 最多 的变量之一了。
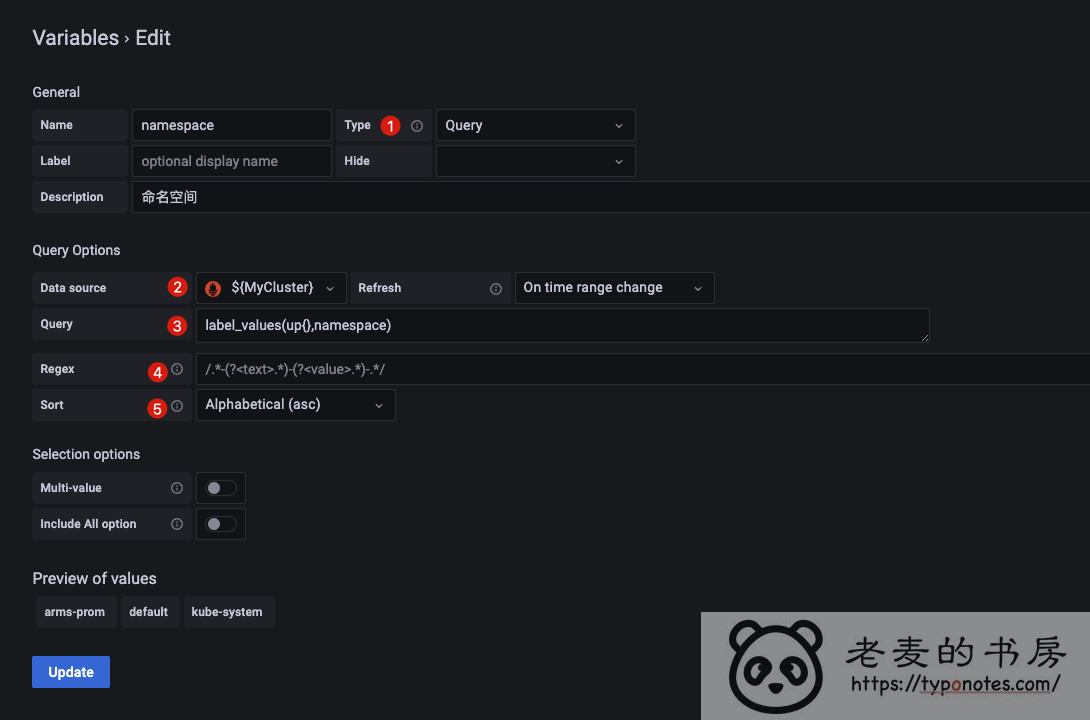
Type选择Query。 通过查询获得结果。- 还需选择
DataSource, 不同的 数据源类型 语句对应的查询语句的语法肯定是不一样的, 这个很好理解。 这里我们选择刚才创建的变量${MyCluster}。 - 变量的
Refresh刷新时机。 是 加载面板 或者 时间范围变化 触发, 根据各自的情况选择。 - 过滤依旧是
Regex, 使用的 Google/re2 的正则表达语法。 Sort排序通常选 Alphabetical(asc) , 依据字母表顺序排列。
2.3. label_values 和 query_result
需要重点强调一下的是 label_values 和 query_result 都是 Grafana 针对 Prometheus 的语法,
Prometheus template variables
, 只能在 Grafana 上使用。
这两个 方法/函数 都可以通过 Grafana 在 Prometheus 进行数据查询, 并返回数据。 但是一些差异。
label_values
这里有一个很重要的 方法/函数: label_values, 可以提取一个 标签。
语法很简单
label_values( 向量, 标签名)
例如上图中我们使用的条件, 以获取 namespace 的值
| |
在向量中, 查询条件是可以 扩展 的, 也是可以使用 变量 的。 例如这里通过提出 job 的值的时候, 使用了变量 namespace 的值。
| |
这应该可以算作 Chained Variable/链接变量 , 理论上是 无限 嵌套的, 但最好这种变量查询 不要超过 5-10 层(主要还是看每次查询的数据量)。
query_result
关于 query_result 我还没搞清楚到底要怎么用, 以及用在什么地方。
按照官方的说法: label_vaules 不支持查询, 因此可以使用 query_result 查询结果, 并通过 正则 过滤。
query_result(topk(5, sum(rate(up[1m])) by (instance)))
官方在这里有一个案例 Use interval and range variables , 有兴趣可以自己了解一下。
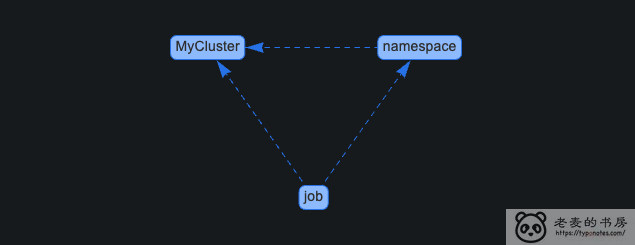
2.4. 变量的依赖关系
话说回来, 所有变量创建完成之后, 可以在 变量管理 界面, 点击右上角的 Show Dependencies 查看变量之间的以来关系。
2.5. 使用变量
使用变量很简单, 将变量替换在对应的地方就可以了。
这是替换后
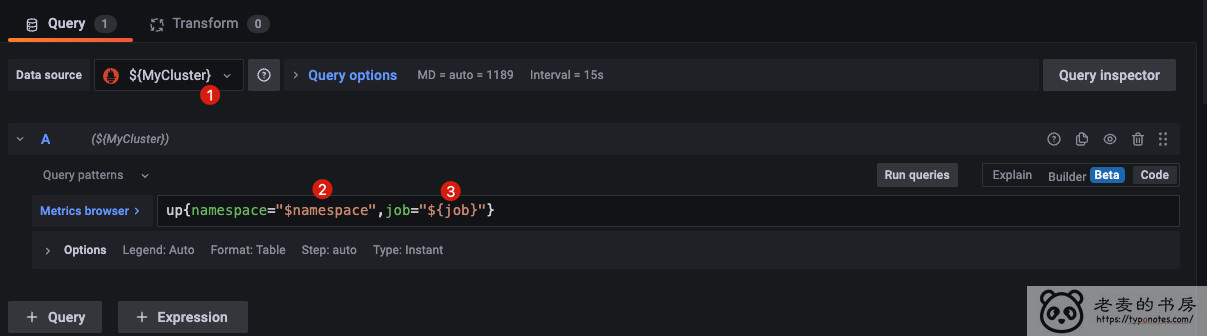
这是替换前
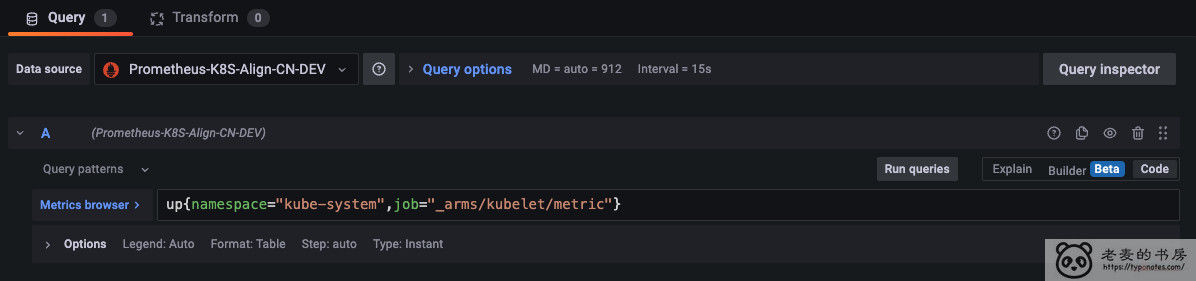
3. 变量的语法
这里说说变量的基础语法。
$variable这是最基本的用法。${variable}可以使用这种方式将变量包裹起来。 通常用于有歧义表达式。 例如${variable}_1与$variable_1就是两个完全不同的含义。 这个点 Shell 类似。${variable:<format>}可以变量进行不同类型的格式化。 要注意 格式化 的方法是 Grafana 提供并限制了的。
可以点击链接到官网, 查看其他 更高级变量的语法 。
- 原文链接:https://typonotes.com/posts/2023/06/08/grafana-variable-management/
- 本文为原创文章,转载注明出处。
- 欢迎 扫码关注公众号
Go与云原生或 订阅网站 https://typonotes.com/ 。 - 第一时间看后续精彩文章。觉得好的话,请猛击文章右下角「在看」,感谢支持。


