172.16.0.20 hadoop001
172.16.0.106 hadoop002
172.16.0.240 hadoop003
1
2
3
4
5
| cat >> /etc/hosts <<"EOF"
172.16.0.20 hadoop001
172.16.0.106 hadoop002
172.16.0.240 hadoop003
EOF
|
安装 java
1
2
3
4
5
6
7
8
9
10
11
12
13
| mkdir -p /opt/modules && cd $_
wget -c https://dl.example.com/jdk-8u201-linux-x64.tar.gz
tar xf jdk-8u201-linux-x64.tar.gz
mv jdk1.8.0_201/ /usr/local/
cat >> /etc/profile <<"EOF"
export JAVA_HOME=/usr/local/jdk1.8.0_201
export PATH=$JAVA_HOME/bin:$PATH
EOF
source /etc/profile
java -version
|
安装 zookeeper
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| mkdir -p /opt/modules && cd $_
wget -c https://dl.example.com/zookeeper-3.4.13.tar.gz
tar xf zookeeper-3.4.13.tar.gz
mkdir -p /data/bigdata
mv zookeeper-3.4.13 /data/bigdata/zookeeper
cd /data/bigdata/zookeeper/conf
cat > zoo.cfg <<"EOF"
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/bigdata/data/zookeeper
clientPort=2181
server.1=hadoop001:2888:3888
server.2=hadoop002:2888:3888
server.3=hadoop003:2888:3888
EOF
mkdir -p /data/bigdata/data/zookeeper
echo 3 > /data/bigdata/data/zookeeper/myid
cd ..
./bin/zkServer.sh start
|
安装 hdfs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| mkdir -p /opt/modules/ && cd $_
wget -c https://dl.example.com/hadoop-3.1.2.tar.gz
tar xf hadoop-3.1.2.tar.gz
mv hadoop-3.1.2 /data/bigdata/hadoop
cat >> /etc/profile <<"EOF"
export HADOOP_HOME=/data/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
EOF
source /etc/profile
## 配置参数
cd /data/bigdata/hadoop
|
hdfs 配置
core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/bigdata/data/hadoop/data</value>
</property>
</configuration>
|
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
<configuration>
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- 集群中 NameNode 节点 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop003:8020</value>
</property>
<!-- 集群中 NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop002:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop003:9870</value>
</property>
<!-- 集群中 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<!-- 访问代理类: client 用于确定 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制, 即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要使用 ssh 密钥登录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
|
手动启动 HDFS 和 激活 NameNode 为 Active
在每个节点上启动 journalnode
1
2
3
| > hadoop001 # hdfs --daemon start journalnode
> hadoop002 # hdfs --daemon start journalnode
> hadoop003 # hdfs --daemon start journalnode
|
启动 namenode
- 在 nn1 节点上格式化, 并启动
1
2
| > hadoop001 # hdfs namenode -format
> hadoop001 # hdfs --daemon start namenode
|
- 在 nn2, nn3 上同步 nn1 的元数据, 并启动
1
2
3
4
5
| > hadoop002 # hdfs namenode -bootstrapStandby
> hadoop003 # hdfs namenode -bootstrapStandby
> hadoop002 # hdfs --daemon start namenode
> hadoop003 # hdfs --daemon start namenode
|
启动 datanode
1
2
3
| > hadoop001 # hdfs --daemon start datanode
> hadoop002 # hdfs --daemon start datanode
> hadoop003 # hdfs --daemon start datanode
|
将 nn1 切换成 Active
1
| > hadoop001 # hdfs haadmin -transitionToActive nn1
|
查看是否为 Active
1
| > hadoop002 # hdfs haadmin -getServiceState nn2
|
HDFS-HA 自动模式切换 Active
自动故障转移依赖 zookeeper 和 ZKFailoverController(ZKFC)
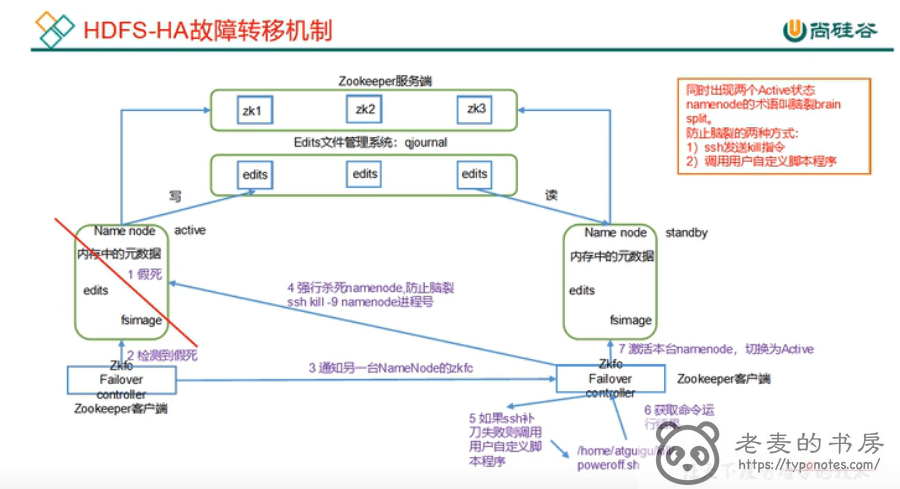
配置变更
增加自动转移相应的配置
hdfs-site.xml 配置
1
2
3
4
5
| <!-- 开启自动转移配置 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
|
core-site.xml 配置
增加 zk 链接地址
1
2
3
4
5
| <!-- 增加 zk 链接地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
|
重启服务以加载配置
停止服务
1
| > hadoop001 # ./sbin/stop-dfs.sh
|
官方提供的集群操作命令, 只需要在任意一台上执行即可
不建议使用 root 启动服务
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Stopping ZK Failover Controllers on NN hosts [hadoop001 hadoop002 hadoop003]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
临时解决方案
1
2
3
4
| export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
|
启动 zk
1
2
3
| > hadoop001 # ./bin/zkServer.sh start
> hadoop002 # ./bin/zkServer.sh start
> hadoop003 # ./bin/zkServer.sh start
|
初始化 zkfc
1
| > hadoop001 # hdfs zkfc -formatZK
|
启动服务
1
| > hadoop001 # ./sbin/start-dfs.sh
|
官方提供的集群操作命令, 只需要在任意一台上执行即可
测试
1
2
3
4
5
6
7
8
9
10
11
| # jps
22368 JournalNode
22036 DataNode
22805 Jps
1079 WrapperSimpleApp
3512 QuorumPeerMain
21836 NameNode
22686 DFSZKFailoverController
# kill -15 21836
|
文件上传测试
使用命令行上传
1
2
3
4
5
6
7
|
# 直接上传
hadoop fs -put README.md /
# api 地址上传, 注意 hdfs://mycluster 就是前面配置文件中的地址
hadoop fs -put NOTICES.md hdfs://mycluster/
|
使用 web 页面上传
报错没有权限
Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
先开始一直纠结我是用 root 用户登录操作的,为什么会是dr.who?
dr.who其实是 hadoop 中 http 访问的静态用户名,并没有啥特殊含义,可以在 core-default.xml 中看到其配置, hadoop.http.staticuser.user=dr.who
我们可以通过修改 core-site.xml ,配置为当前用户
1
2
3
4
| <property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
|
https://www.codeleading.com/article/26545630323/
Hbase 安装
部署 hbase 安装包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| mkdir -p /opt/modules/ && cd $_
### 1.7.1
# wget -c https://dl.example.com/hbase-1.7.1-bin.tar.gz
# tar xf hbase-1.7.1-bin.tar.gz
# mv hbase-1.7.1 /data/bigdata/hbase
#### 2.4.11
wget -c https://dl.example.com/hbase-2.4.11-bin.tar.gz
tar xf hbase-2.4.11-bin.tar.gz
mv hbase-2.4.11 /data/bigdata/hbase
cd /data/bigdata/hbase/
|
修改配置参数
修改集群控制列表
1
2
3
4
5
| cat > conf/regionservers << EOF
hadoop001
hadoop002
hadoop003
EOF
|
修改 hbase-env.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| cat > conf/hbase-env.sh <<EOF
# JAVA_HOME
export JAVA_HOME=${JAVA_HOME}
# Extra Java runtime options.
# Below are what we set by default. May only work with SUN JVM.
# For more on why as well as other possible settings,
# see http://wiki.apache.org/hadoop/PerformanceTuning
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# 使用外部 zk
export HBASE_MANAGES_ZK=true
EOF
|
修改 hbase-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
<configuration>
<!-- 文件存储在 hdfs 的目录路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<!-- 是否为分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动, 之前版本没有 port , 默认端口是 60000 -->
<!-- 服务端口 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- zookeeper 集群链接地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop001,hadoop002,hadoop003</value>
</property>
<!-- zookeeper 目录路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/bigdata/data/zookeeper</value>
</property>
<!-- regionserver hostname -->
<property>
<name>hbase.regionserver.hostname</name>
<value>hadoop001</value>
</property>
<!-- master hostname -->
<property>
<name>hbase.master.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
|
软连接 hdfs 配置
1
2
3
| ln -s /data/bigdata/hadoop/etc/hadoop/hdfs-site.xml /data/bigdata/hbase/conf/hdfs-site.xml
ln -s /data/bigdata/hadoop/etc/hadoop/core-site.xml /data/bigdata/hbase/conf/core-site.xml
|
为什么部署 hbase 的时候要复制 hdfs 的配置文件?
为了在使用 hbase 客户端的时候, hdfs 配置文件中 关于 client 部分 的自定义配置文件能生效。 因此这个操作不是必须的, 尤其是在使用代码操作 hbase 的时候。
Procedure: HDFS Client Configuration
Of note, if you have made HDFS client configuration changes on your Hadoop cluster, such as configuration directives for HDFS clients, as opposed to server-side configurations, you must use one of the following methods to enable HBase to see and use these configuration changes:
1. Add a pointer to your HADOOP_CONF_DIR to the HBASE_CLASSPATH environment variable in hbase-env.sh.
2. Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
3. if only a small set of HDFS client configurations, add them to hbase-site.xml.
An example of such an HDFS client configuration is dfs.replication. If for example, you want to run with a replication factor of 5, HBase will create files with the default of 3 unless you do the above to make the configuration available to HBase.
启动 hbase
启动单机 master
1
| > hadoop001 # ./bin/hbase-daemon.sh start master
|
访问 hadoop001 地址查看 master status : http://172.16.0.20:16010/master-status
启动单机 regionserver
1
| > hadoop001 # ./bin/hbase-daemon.sh start regionserver
|
启动其他 regionserver
报错
2022-03-22 19:16:24,428 INFO [regionserver/localhost:16020] regionserver.HRegionServer: reportForDuty to master=localhost.vm,16000,1647947765808 with isa=localhost.vm/127.0.1.1:16020, startcode=1647947783154
2022-03-22 19:16:24,489 WARN [regionserver/localhost:16020] regionserver.HRegionServer: error telling master we are up
org.apache.hbase.thirdparty.com.google.protobuf.ServiceException: java.net.ConnectException: Call to address=localhost.vm/127.0.1.1:16000 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.AbstractChannel$AnnotatedConnectException: finishConnect(..) failed: Connection refused: localhost.vm/127.0.1.1:16000
解决方法
配置 /etc/hosts
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.16.0.20 hadoop001 hbase-demo-0001
172.16.0.106 hadoop002 hbase-demo-0002
172.16.0.240 hadoop003 hbase-demo-0003
#127.0.1.1 hbase-demo-0001 hbase-demo-0001
#127.0.1.1 localhost.vm localhost
使用 systemd 管理 HMaster 和 HRegionServer
在使用 systemd 管理 HMaster 和 HRegionServer 的时候, 设置启动命令需要使用 foregrand_start 前台启动方式。 否则程序会自动退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# hbase-master.service.j2
[Unit]
Description=hbase master
[Service]
User={{ username }}
Group={{ username }}
Environment="JAVA_HOME=/data/bigdata/java"
Environment="HBASE_HOME={{ HBASE_DIR }}/hbase"
WorkingDirectory={{ HBASE_DIR }}/hbase
ExecStart={{ HBASE_DIR }}/hbase/bin/hbase-daemon.sh --config {{ HBASE_DIR }}/hbase/conf foreground_start master
ExecStop={{ HBASE_DIR }}/hbase/bin/hbase-daemon.sh --config {{ HBASE_DIR }}/hbase/conf stop master
Restart=on-success
# Restart service after 10 seconds if the dotnet service crashes:
RestartSec=10
KillSignal=SIGINT
SyslogIdentifier=hbase-master
[Install]
WantedBy=multi-user.target
|
在前后台启动这一点上, systemd , supervisor 和 docker entrypoint 上是一样的。


